介绍和实践 puppeteer 的使用场景
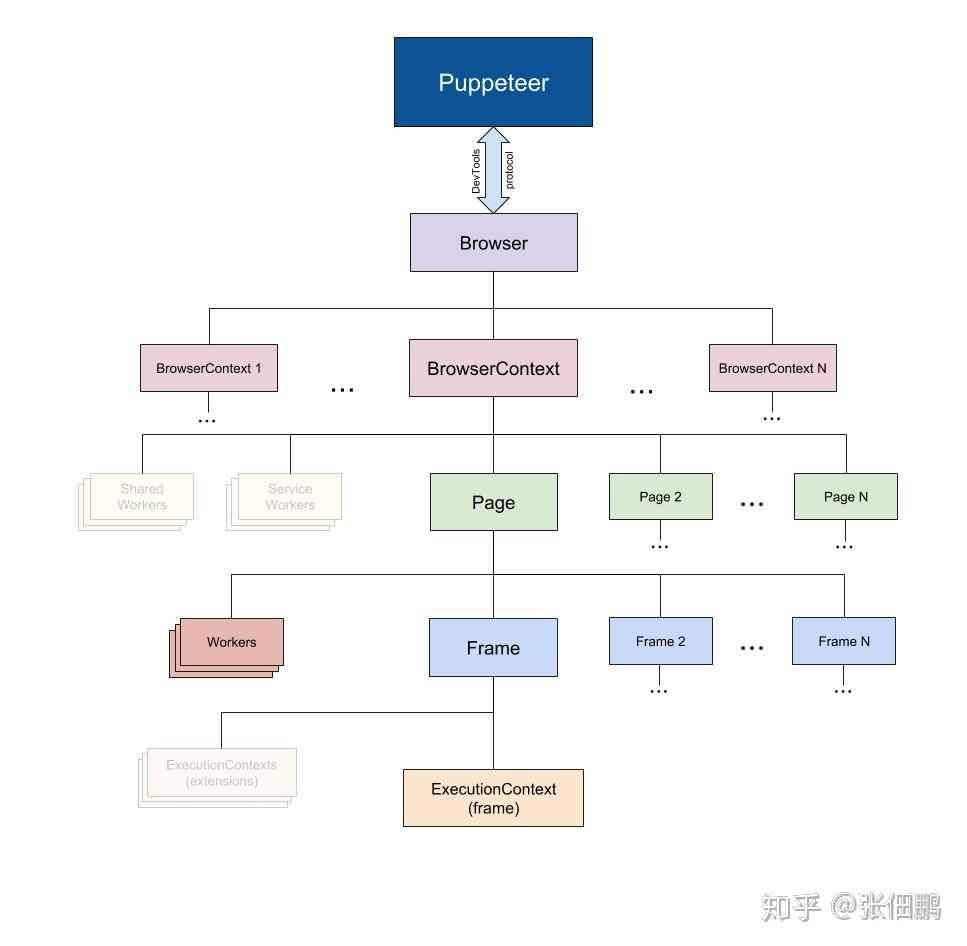
Puppeteer 定义
- Puppeteer 是 Node.js工具引擎
- Puppeteer 提供了一系列 API,通过 Chrome DevTools Protocol 协议控制 Chromium/Chrome 浏览器的行为
- Puppeteer 默认情况下是以 headless 启动 Chrome 的,也可以通过参数控制启动有界面的 Chrome,特点是操作 Dom 可以完全在内存中进行模拟,可以只在 V8 引擎中处理而不打开浏览器
- Puppeteer 默认绑定最新的 Chromium 版本,也可以自己设置不同版本的绑定Puppeteer 让我们不需要了解太多的底层 CDP 协议实现与浏览器的通信
主要实现原理
Puppeteer 是基于 chrome devtools protocal 进行的二次封装,即我们能够手动对浏览器进行的操作基本上都可以用 Puppeteer 来实现,并且可以使用无界面版(headless)来操作浏览器,比方说,手动执行登录、打开网络面板、模拟设备、分析页面性能等操作,都可以通过调用 Puppeteer 的 API 来完成。
headless broswer:即在无界面的环境中运行,通过命令行或者程序语言操作 Chrome
应用场景
- 爬取SPA应用,并生成预渲染内容(即“SSR” 服务端渲染)
- 自动化表单提交、UI测试、键盘输入等
- 自动化测试Web页面,捕获站点的时间线等信息,帮助分析网站性能问题
- 网页截图,或生成 pdf
Puppeteer API
Puppeteer 的大部分 API 的返回值都是 Promise,故推荐使用 async await 来处理异步操作。Puppeteer 的 API 包含以下类:
| 类名 | 描述 | 实践 |
|---|---|---|
| Puppeteer | 主要用于创建一个浏览器实例,也可以用来下载新的 Chromium,或者设置浏览器的默认参数 | ✅ |
| BrowserFetcher | 用于下载和管理 Chromium | ❌ |
| Browser | 对应一个浏览器实例,一个 Browser 可以包含多个 BrowserContext,可以创建一个或多个 Page | ✅ |
| Page | 表示一个 Tab 页面,通过 browserContext.newPage()/browser.newPage() 创建 | ✅ |
| Worker | 用于处理 WebWorker | ❌ |
| Tracing | 用于分析性能 | ✅ |
| Dialog | 存在于 page 的 dialog 事件回调中,表示调用弹窗后的对象,包括 alert, beforeunload, confirm 和 prompt | ❌ |
| ConsoleMessage | 存在于 page 的 console 事件回调中,表示调用 console.log 等方法后的对象 | ❌ |
| Frame | 一个框架,每个页面有一个主框架(page.MainFrame()),也可以多个子框架,主要由 iframe 标签创建产生的 | ❌ |
| ExecutionContext | 是 javascript 的执行环境,每一个 Frame 都一个默认的 javascript 执行环境 | ❌ |
| JSHandle | 对应 DOM 中的 javascript 对象,ElementHandle 继承于 JsHandle,由于我们无法直接操作 DOM 中对象,所以封装成 JsHandle 来实现相关功能 | ❌ |
| ElementHandle | 对应 DOM 的一个元素节点,通过该该实例可以实现对元素的点击,填写表单等行为,我们可以通过选择器来获取对应的元素 | ✅ |
| Request | 在 page.setRequestInterception 方法中使用,可以处理页面的请求 | ✅ |
| Response | 表示页面接收到的响应 | ✅ |
| CDPSession | 用于直接和 Devtools 通信 | ❌ |
| Coverage | 用于分析 js 和 css 的代码被页面使用的比例 | ✅ |
| TimeoutError | 超时错误 | ✅ |
Page
Puppeteer中最主要的API是Page,无论是爬虫还是自动化测试,都离不开Page
以下列出常用的方法:
| 方法名 | 描述 |
|---|---|
| setCookie | 设置cookie信息 |
| emulate | 根据指定的参数和 user agent 生成模拟器 |
| goto | 跳转到目标网址 |
| waitForSelector | 等待指定的选择器匹配的元素出现在页面中 |
| $$ | 此方法在页面内执行 document.querySelectorAll。如果没有元素匹配指定选择器,返回值是 []。 |
| tap | 点击选择的元素。如果有多个匹配的元素,点击第一个 |
| click | 此方法找到一个匹配 selector 选择器的元素,如果需要会把此元素滚动到可视,然后通过 page.mouse 点击它。 如果选择器没有匹配任何元素,此方法将会报错。 |
| touchScreen | 将元素移动到可视区域 |
| evaluate | 在浏览器环境中执行函数 |
| type | 模拟手动输入 |
| tracing | 创建一个可以在 Chrome DevTools or timeline viewer 中打开的跟踪文件 |
| metrics | 返回页面性能指标内容 |
Puppeteer 实践
- UI 自动化测试
- 爬虫
- 应用性能测试
- 网页截图,或生成 pdf
首先是【安装】:
puppeteer 实际上操作的是 chrome,所以直接安装 puppeteer 的话会非常大,我们可以分开安装
1 | yarn add puppeteer-core --dev |
根据 puppeteer 依赖的 chromium 下载对应版本(查看 puppeteer-core 的 package.json,选择 chromium_revision),也可以直接使用chrome
【引入】
1 | const puppeteer = require("puppeteer-core"); |
上面的代码是使用 puppeteer 的基本步骤,首先初始化一个实例,每次初始化实例的时候都重新启动一个浏览器实例,并且清空上一次信息。当然也可以使用已经存在的实例。使用 puppeteer.connect();
区别Puppeteer.launch和Puppeteer.connect:
| 方法 | 区别 | 过程 |
|---|---|---|
| Puppeteer.launch() | 用于启动Chromium实例,每次启动一个新的浏览器,同一个域下的cookie不共享,一个浏览器下可以使用newPage()的方式打开多个page | 启动Chromium->打开tab页->运行代码->关闭tab页->关闭Chromium |
| Puppeteer.connect() | 链接已存在的实例(browser.wsEndpoint()返回浏览器 websocket 的地址),减少了重启的时间 | 连接Chromium->打开tab页->运行代码->关闭tab页 |
UI 自动化测试
如上面所言,凡是能够手动执行的操作,我们都可以通过 Puppeteer 来执行,我们可以把 Puppeteer 理解为一个集成测试库,为了保证每次的改动不影响其他页面,我们可以将每次进行的主流程操作改为自动执行,点击响应,点击跳转。
下面我们以掘金登录流程为例,执行手动输入用户名密码:
1 | const page = await browser.newPage(); |
使用有界面的模式下观察,你会发现浏览器自动输入的过程,一般情况下,通过用户名和密码输入的可以直接通过这种方式完成,当然也有手机号验证码的方式,意味着输入完成手机号,还有和 node 交互的过程,我选了一个同步交互工具:
1 | yarn add readline-sync --dev |
使用方法如下:
1 | await page.tap(".getCode"); |
这种方式不好的地方在于每次打开一个实例都需要输入一次验证码,所以 puppeteer 也为我们提供了设置 http header 的方式:
1 | await page.setCookie({ |
这里如果想要设置 cookie,一定要有 url,不然会设置失败
生成截图
自动化登录的过程完成了,其实 puppeteer 还有一个常用的操作,就是在运行过程中生成截图,这个很方便,一方面可以帮助我们观察页面在各个阶段的展现,另一方面,我们可以设置设备型号,puppeteer 模拟了 138 种手机型号,方便做【兼容性测试】,在设备不充足的情况下,这是非常好的方法,而且,每次给 UI 走查都要从手机上截图,然后打包也很麻烦,因为 UI 出的尺寸,对比时要按照固定设备比对,那么我们就可以使用 puppeteer 生成截图,再压缩了。
1 | const devices = require("puppeteer-core/DeviceDescriptors"); |
爬虫
爬虫和其他 request 爬虫的区别,传统爬取下来的网页是二进制的格式,需要我们自己应对编码问题,并且用 cheerio 解析 dom 文档。
而 puppeteer 省去了这一步,可以直接获取 dom 结构,进而得到我们想要得到的数据,而且因为puppeteer可以模拟人为操作,拦截请求,所以我们也可以很方便的通过puppeteer来分析接口,爬取数据。
node http 模块爬虫:
1 | const http = require("https"); |
puppeteer 爬取数据过程:
1 | await page.goto(path); |
Page.evaluate函数,回调里面的函数创造了一个浏览器执行环境,在里面,可以使用原生的方法获取DOM属性(如果网站有jquery也可以直接用$获取元素,没有的话需要外部注入),这个函数的返回的数据将会以Promise的形式返回到外部。既然函数内部可以控制浏览器,那么也可以通过代码改变原来的表现行为,比如说我们在内部使用console,你不会在控制台内看到打印的值,在关闭headless模式的时候,会发现在浏览器的devtools console里面发现我们刚刚打印的值。
1 | v.querySelector('.value').innerHTML = '车型不匹配'; |
执行了上述代码,页面上的内容会被我们改变,这种通常用于测兼容性问题,我们自定义字符的长度和格式,观察显示情况,和直接在浏览器上改变内容是一样的。总而言之,你可以在浏览器里执行任何你想要运行的 javascript 代码。
在执行 page.evaluate 的时候,函数会先被序列化成字符串,传递给浏览器的 JS 运行时,然后再执行。
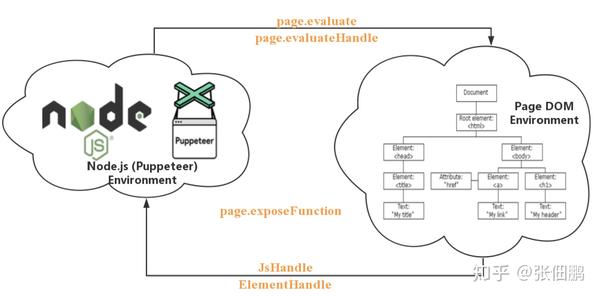
在使用 Puppeteer 时我们总共有两个环节:运行 Puppeteer 的 Node.js 环境和 Puppeteer 操作的页面 Page DOM:
- 首先 Puppeteer 提供了很多有用的函数去 Page DOM Environment 中执行代码
- 其次 Puppeteer 提供了 ElementHandle 和 JsHandle 将 Page DOM Environment 中元素和对象封装成对应的 Node.js 对象,这样可以直接用这些对象的封装函数进行操作 Page DOM
网页性能分析
通常情况下我们进行网页性能分析(运行时运行时性能表现,而不是下载页面表现),可以直接使用 devtools 的 performance 进行录制分析,在 puppeteer 中我们可以通过执行命令的方式得到页面的性能信息。
1 | await page.tracing.start({ path: "./trace.json" }); |
得到的是一份比较全的性能信息文件,我们可以在 devtools 的 performance 里上传生成的 trace.json 文件,分析各个阶段的性能信息。(trace.json 对于中型应用可能几兆)
也可以代码中读取必要信息,进行分析,如进行某个 css 文件执行的时间:
1 | const name = "main.css"; |
另外进行页面性能分析,可以使用 window.performance,计算首屏加载时间、request 请求耗时、解析 dom 树耗时等
1 | JSON.parse(await page.evaluate( |
puppeteer 本身也为我们提供了 metrics 方法, 用以获得各个性能指标内容:
1 | { |
page.metrics()和page._client.send(‘Performance.getMetrics’)做的是一样的操作,相当于对chrome devtools protocal做的一层封装
page.mertrics和window.performance有什么不一样的么?
我的理解,前者给出的是网页的性能指标项和指标值,包含加载和运行时的各个阶段的表现,在于帮助检测性能瓶颈,提供了更多的页面加载时更详细的时间点的表现
后者给出的是运行时的表现,每个时间节点的数据,如果需要知道性能,需要用时间节点去计算。
比方说通过window,performance可以通过domContentLoadedEventEnd - fetchStart计算首屏加载时间,但是mertrics可以给出的是首屏有意义渲染时间,这个时间FMP = 最大布局变化时的绘制
代码覆盖率
Coverage 收集相关页面使用的 JavaScript 和 CSS 部分的信息。使用 JavaScript 和 CSS 覆盖率来获取初始百分比的例子
返回的是,渲染当前页面使用的js代码和样式代码。即初始化时执行的代码比例,执行了哪部分。原理我也不太清楚,测试了下项目的每个页面覆盖率都是40%左右,网上有基于这个开发的自动化测试覆盖率的例子,puppeteer-coverage
1 | // 启用 JavaScript 和 CSS 覆盖 |
总结
上面介绍了puppeteer的使用,实际上,在我们的工作中,可以封装成一系列的小工具,比如一直迭代的项目,会有常用的测试case,我们可以封装一个自动化测试的工具,每次发布前自己执行一遍确保改动不影响流程。还有一些服务端统计报表的功能,就可以使用浏览器的绘制功能绘出的表格会更流畅。

